RAG System Architecture
How we prevent AI hallucinations with grounded manuals
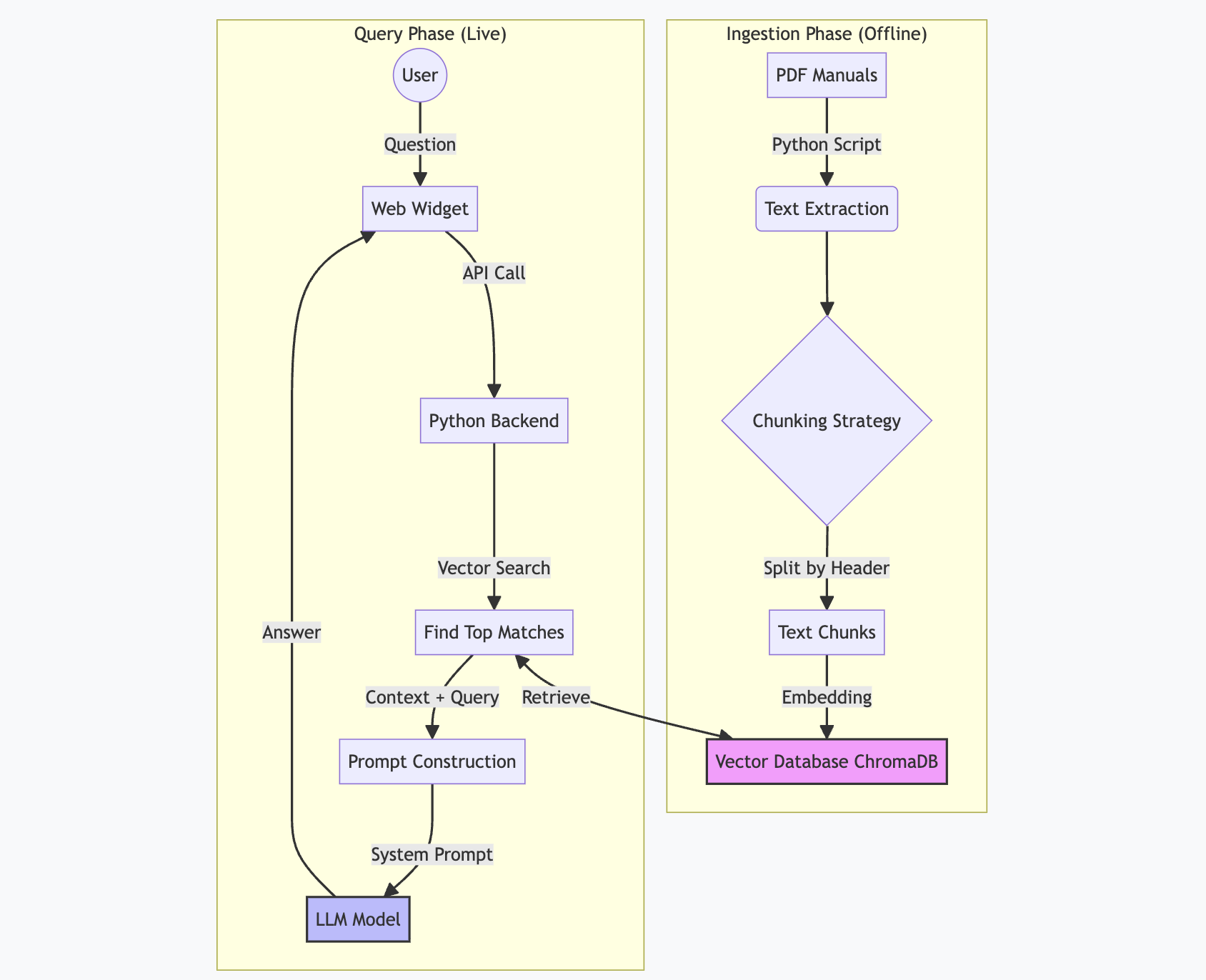
How it Works: The "Anti-Hallucination" Design
This architecture is specifically designed to prevent the AI from inventing facts (hallucinations), a common problem with generic ChatGPT implementations. It forces the system to act as a strict summarizer of your specific technical manuals.
1. Ingestion Phase (The Foundation)
We don't just dump text blindly. The Chunking Strategy is critical for accuracy. Instead of splitting by arbitrary character counts (e.g., every 500 chars), we utilize a semantic splitter script that breaks documents down by headers and topics (e.g., "Technical Specifications", "Pinout Configuration"). This ensures that each retrieved chunk contains complete, self-contained information about a specific subject.
2. The Trap (Prompt Engineering)
The "Secret Sauce" isn't just the database, it's the strict system prompt sent to the LLM. It dictates the behavior rules:
System: "You are a helpful technical support assistant for El-Man Broadcast Equipment."
Context: {INSERT_RETRIEVED_CHUNKS_HERE}
Instruction: "Answer the user's question using ONLY the information in the Context provided above. If the answer is not explicitly written in the Context, state 'I cannot find this information in the manuals.' Do not guess."
3. The Result
- User asks: "Does the NTP server support PTPv2?"
- Retrieval: System finds chunks about NTP redundancy and specs. None mention PTPv2.
- LLM Analysis: Sees context about NTP, but no PTPv2 keywords in the allowed text.
- LLM Output: "I cannot find information about PTPv2 support in the manuals." (Instead of inventing "Yes, it might support it" to be helpful).